Pouvons-nous faire confiance aux décisions prises par l'Intelligence Artificielle ? (1/3)
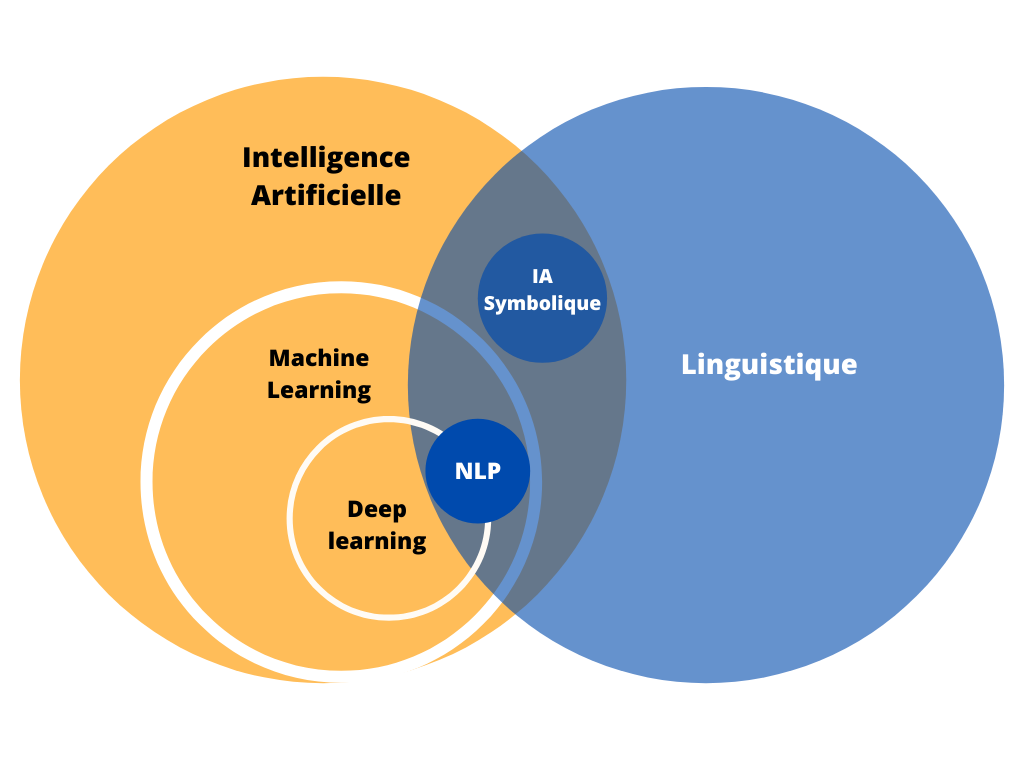
Comprendre l'IA connexionniste
5 min de lecture
L’Intelligence Artificielle (IA) apparaît comme le nouvel enjeu technologique incontournable dans lequel un grand nombre d’entreprises investissent déjà massivement. Ce domaine, qui a vu le jour il y a plus d’un demi-siècle, révolutionne aujourd’hui notre société. Elle accompagne de plus en plus des professions techniques et permet de prendre des décisions importantes.
À quel point pouvons-nous faire confiance aux décisions prises par l’Intelligence Artificielle ? Et avant tout, à quoi fait-on référence lorsqu’on parle d’ “Intelligence Artificielle” ?
L’équipe R&D de CoperBee relève le défi de répondre à cette interrogation complexe au travers d’une explication en trois parties :
-
Qu’est-ce que l’IA connexionniste ?
-
Pourquoi l’IA symbolique ne suffit-elle pas ?
-
Peut-on avoir confiance en ces outils ?
1 - Qu'est-ce que l'IA connexionniste ?
Commençons par définir certains concepts pour savoir de quoi on parle :
C’est quoi l‘IA ? Elle est définie dans le dictionnaire Larousse comme “l’ensemble de théories et de techniques mises en œuvre en vue de réaliser des machines capables de simuler l’intelligence humaine.”
Cette semaine, nous mettons l’accent sur l’IA qui fait le plus parler d’elle depuis une décennie : l’IA connexionniste, celle des réseaux de neurones. Pour illustrer cette approche, on peut faire une analogie avec les neurones biologiques, qui font circuler de l’information à travers chaque connexion. On parle généralement de “Machine Learning” et de “Deep Learning” (les “réseaux de neurones profonds“). Si les deux termes sont parfois utilisés de manière interchangeables, quelques différences fondamentales les distinguent.
Similarité
Les deux approches reposent sur une phase d’entraînement à partir d’exemples annotés (= associés aux“bonnes réponses”) qui permettent de construire des modèles statistiques. Il s’agit du cœur de l’IA qui permettra par la suite, d’appliquer un ensemble de calculs pour que les prédictions (= réponses associées à de futures données) soient les plus justes possibles.
Différence
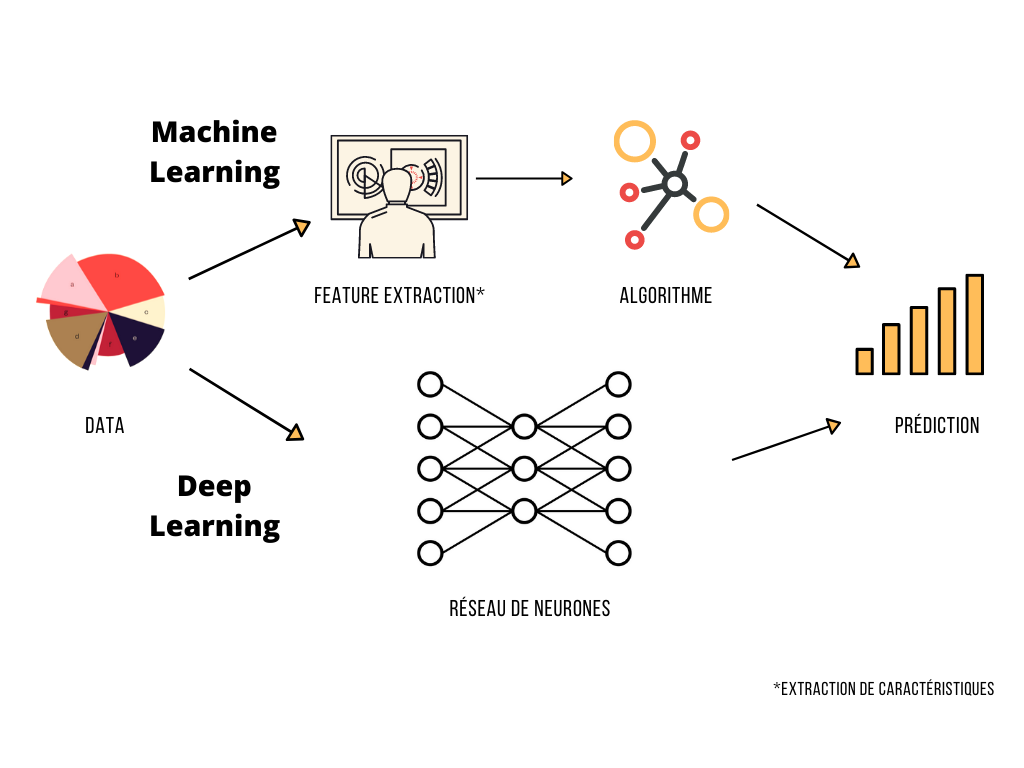
Historiquement, le machine learning a fait émerger la première famille de réseaux de neurones. Un exemple typique est la prédiction du prix des maisons, rendue possible à partir d’informations telles que le “nombre de chambres, la surface au sol, le quartier…” collectées sur des maisons qui ont déjà été vendues. Les informations jugées importantes pour arriver aux meilleures prédictions possibles sont sélectionnées par un opérateur humain doté de connaissances expertes, c’est ce qu’on appelle la « feature engineering » ou « feature extraction ».
Le Deep Learning est une évolution du Machine Learning, qui dépend moins de connaissances humaines relatives aux données. En effet, il ne s’agit pas d’un opérateur expert qui choisirait les caractéristiques importantes mais la machine elle-même qui va établir ses propres pondérations. Cette approche nécessite généralement une grande quantité de données pour atteindre de bons scores,
tandis que le nombre d’étapes de calculs nécessaires en est donc démultiplié. Cela implique des coûts de traitement bien plus importants qu’avec le Machine Learning plus traditionnel. Ceci explique d’ailleurs l’avènement du Deep Learning ces dernières années : la puissances de calculs des machines modernes offrent des possibilités jusqu’alors inenvisageables.
Atouts et potentiel
Ce type d’IA a un impact spectaculaire : sa capacité à prédire des données différentes de celles de l’apprentissage permet de résoudre des tâches complexes.
Chez CoperBee, nous sommes spécialistes en Natural Language Processing (NLP, ou TALN en français pour Traitement Automatique des Langues Naturelles), prenons donc le temps d’observer un exemple concret : l’analyse de sentiments.
L’analyse de sentiments est une tâche très commune en NLP, dont l’objectif est d’identifier l’opinion d’un texte. Nous faisons appel à bien plus que des règles de grammaire et de vocabulaire pour déterminer si un commentaire exprime une opinion positive ou négative (ou les deux, ou aucune des deux), ce qui rend la tâche complexe pour une machine.
“La petite surprise : la plage à 100m !”
“La petite surprise : la rocade à 100m !”
Ici, seuls les termes “plage” et “rocade” diffèrent, et ils ne sont pas intrinsèquement positifs ou négatifs, c’est notre connaissance du monde qui nous permet de juger si le commentaire exprime une bonne ou une mauvaise surprise.
Inconvénients
Cependant, ce type d’IA est parfois critiqué car ces réseaux de neurones sont de véritables boîtes noires, donnant des résultats parfois inexplicables. Pourtant, le besoin de comprendre les succès et les échecs de ces systèmes est un enjeu de société moderne.
La semaine prochaine, nous développerons le sujet de l’IA symbolique, plus transparente mais moins performante. N’hésitez pas à nous dire en commentaire de cet article s’il vous a été utile, nous serons heureux de répondre à vos remarques.
Notez ce post


Autres articles
In:IA
Pouvons-nous faire confiance aux décisions prises par l’Intelligence Artificielle ? (3/3)
29 avril 2021
Deux familles majoritaires d’IA prennent une place imposante dans notre quotidien et soulève la question de la...
In:IA
Pouvons-nous faire confiance aux décisions prises par l’Intelligence Artificielle ? (1/3)
29 mars 2021
L’Intelligence Artificielle apparaît comme le nouvel enjeu technologique incontournable dans lequel un grand nombre...




















